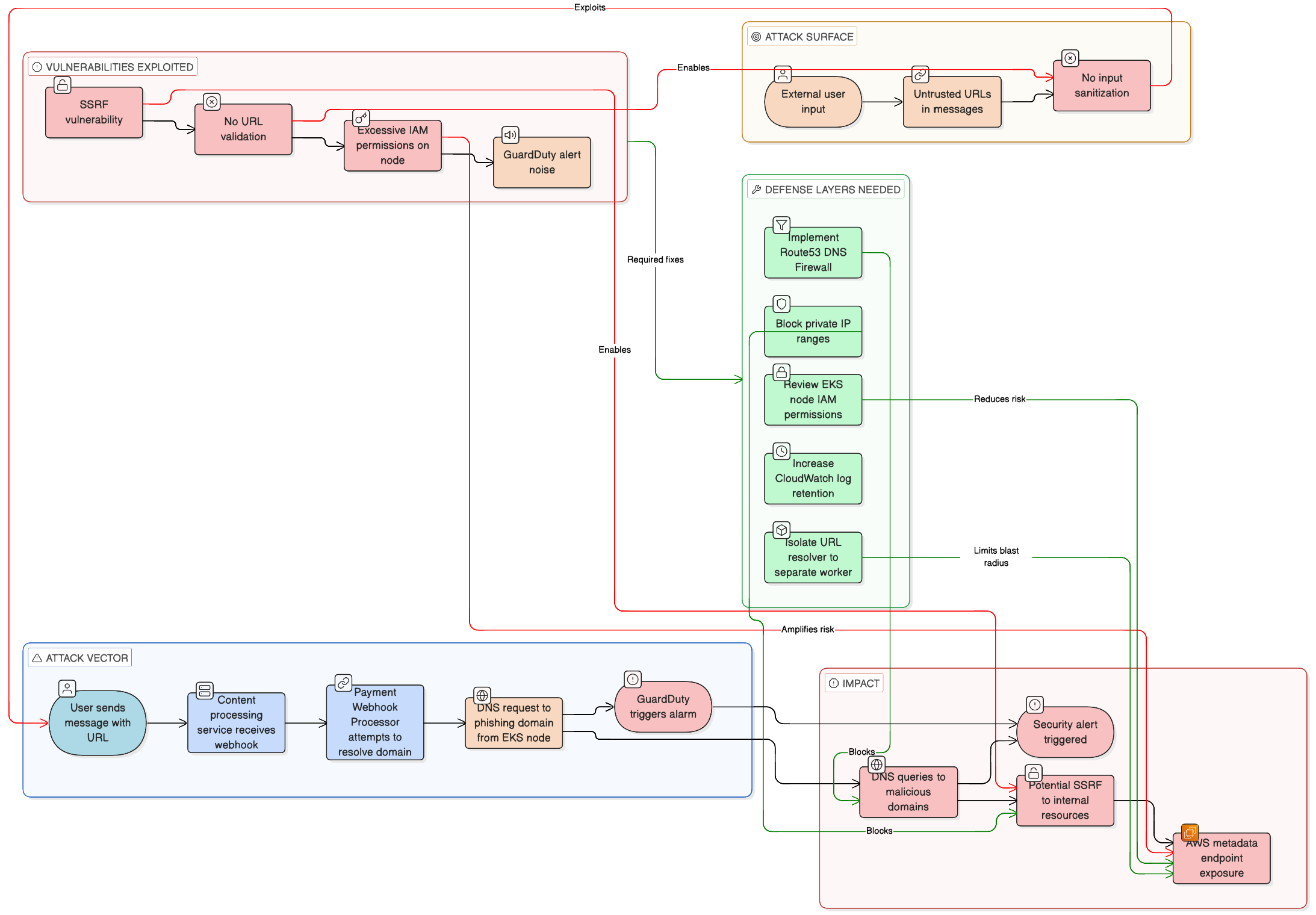
GuardDuty screams about a phishing domain. The node looks fine — no malware, no stolen creds. Often the real story is simpler: your app looked up a URL someone pasted in a message, and that hostname is on a threat list. The alert is still “true” (DNS to a bad name happened), but it is not a hacked cluster.
The uncomfortable part: if you resolve or fetch any user URL with no checks, you also open the door to SSRF — for example a link to 169.254.169.254 (instance metadata) from a worker that uses the node’s IAM role. That is a bigger problem than one noisy finding.
What actually happened (typical chain)
- User sends text with a link (e.g. a shady
.cndomain). - A webhook or message handler picks it up in EKS.
- Some code path (preview, image, “unfurl”) resolves the hostname or pulls the page.
- DNS goes out from the node where the pod runs.
- GuardDuty fires because that domain matches phishing/malware intel.
So: no infection required — just DNS toward a flagged name.
Quick checks when you investigate
App logs — usually the fastest. You should see the same hostname as in the finding, tied to a request or message id:
|
|
From a pod (sanity check):
|
|
Before DNS Firewall: you get real A records. After you block the domain in Route 53 Resolver DNS Firewall, behavior depends on your resolver setup (often empty answer or no resolution).
GuardDuty — you will see the domain, instance, VPC, severity. The exact finding type string varies; the important bit is DNS_REQUEST + domain name. Example shape:
|
|
Fix the app: do not follow private / metadata URLs
Block these before you resolve or fetch: 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 127.0.0.0/8, and 169.254.0.0/16 (covers 169.254.169.254 metadata).
Minimal Python idea — resolve host to IPs, reject bad ranges:
|
|
In production you still want timeouts, redirect limits, and egress rules — DNS rebinding can bite you if you only check the first hop.
Fix the noise: Route 53 DNS Firewall
Use AWS managed domain lists (malware + aggregate threat) in a firewall rule group, then attach it to the VPC where EKS nodes live. Docs: managed domain lists.
Sketch:
|
|
That stops a lot of known-bad names at DNS, before your app even opens TCP.
Bigger win: move “fetch user URLs” to a small worker
Run preview / URL fetch in a separate job with narrow egress and minimal IAM — not on the same path as your main API on nodes that carry fat instance roles.
Practical notes
- Check application logs first when GuardDuty names a domain; it saves hours.
- Raise EKS control plane log retention if yours is short — old node events disappear fast.
- Shrink node IAM — SSRF to metadata is about credentials, not only alerts.
- User-supplied links will eventually hit phishing lists; document that so people do not treat every DNS finding as an incident.
The diagram above is the same story in one screen: how the traffic flows, what breaks, what to add. False positive for “we are hacked,” real work on SSRF, DNS, and IAM.